2 Keep a Record
2.1 Make Sure You Know What You Did
For any kind of formal data analysis that leads to a scholarly paper, whichever model you tend to favor, there are some basic principles to adhere to. Perhaps the most important thing is to do your work in a way that leaves a coherent record of your actions. Instead of doing a bit of statistical work and then just keeping the resulting table of results or graphic that you produced, for instance, write down what you did as a documented piece of code. Rather than figuring out but not recording a solution to a problem you might have again, write down the answer as an explicit procedure. Instead of copying out some archival material without much context, file the source properly, or at least a precise reference to it.
A second principle is that a document, file or folder should always be able to tell you what it is. Beyond making your work reproducible, you will also need some method for organizing and documenting your draft papers, code, field notes, datasets, output files or whatever it is you’re working with. In a world of easily searchable files, this may mean little more than keeping your work in plain text and giving it a descriptive name. It should generally not mean investing time creating some elaborate classification scheme or catalog that becomes an end in itself to maintain.
A third principle is that repetitive and error-prone processes should be automated if possible. (Software developers call this “DRY”, or Don’t Repeat Yourself.) This makes it easier to check for and correct mistakes. Rather than copying and pasting code over and over to do basically the same thing to different parts of your data, write a general function that can be called whenever it’s needed. Instead of retyping and reformatting the bibliography for each of your papers as you send it out to a journal, use software that can manage this for you automatically.
There are many ways of implementing these principles. You could use Microsoft Word, Endnote and SPSS. Or Textpad and Stata. Or a pile of legal pads, a calculator, a pair of scissors and a box of file folders. But software applications are not all created equal, and some make it easier than others to do the Right Thing. For instance, it is possible to produce well-structured, easily-maintainable documents using Microsoft Word. But you have to use its styling and outlining features strictly and responsibly, and most people don’t bother. You can maintain reproducible analyses in SPSS, but the application isn’t set up to do this automatically or efficiently, nor does its design encourage good habits. So, it is probably a good idea to invest some time learning about the alternatives. Many of them are free to use or try out, and you are at a point in your career where you can afford to play with different setups without too much trouble.
The dissertation, book, or articles you write will generally consist of the main text, the results of data analysis (perhaps presented in tables or figures) and the scholarly apparatus of notes and references. Thus, as you put a paper or an entire dissertation together you will want to be able to easily keep a record of your actions as you edit text, analyze data and present results, in a reproducible way. In the next section I describe some applications and tools designed to let you do all of this. I focus on tools that fit together well (by design) and that are all freely available for Windows, Linux and Mac OS X. They are not perfect, by any means—in fact, some of them can be awkward to learn. But graduate-level research and writing can also be awkward to learn. Specialized tasks need specialized tools and, unfortunately, although they are very good at what they do, these tools don’t always go out of their way to be friendly.
2.2 Use Version Control
Writing involves a lot of editing and revision. Data analysis involves cleaning files, visualizing information, running models, and repeatedly re-checking your code for mistakes. You need to keep track of this work. As projects grow and change, and as you explore different ideas or lines of inquiry, the task of documenting your work at the level of particular pieces of code or edits to paragraphs in individual files can become more involved over time. The best thing to do is to institute some kind of version control to keep a complete record of changes to a single file, a folder of material, or a whole project. A good version control system allows you to “rewind the tape” to earlier incarnations of your notes, drafts, papers and code. It lets you keep explore different aspects or branches of a project. In its more developed forms it provides you with some powerful tools for collaborating with other people. And it helps stop you from having directories full of files with confusingly similar names like Paper-1.doc, Paper-2.doc, Paper-conferenceversion.doc, Paper-Final-revised-DONE-lastedits.doc.
In the social sciences and humanities, you are most likely to have come across the idea of systematic version control by way of the “Track Changes” feature in Microsoft Word, which lets you see the edits you and your collaborators have made to a document. Collaborative editing of a single document is also possible through platforms like Google Docs or Quip. True version control is a way to do these things for whole projects, not just individual documents, in a comprehensive and transparent fashion. Modern version control systems such as Mercurial and Git can, if needed, manage very large projects with many branches spread across multiple users. Git has become the de facto standard, and GitHub is a place where software developers and social scientists make their work available, and where you can contribute to ongoing projects or make public your own.
Modern version control requires getting used to some new concepts related to tracking your files, and learning how your version control system implements these concepts. There are some good resources for learning them. Because of their power, these tools might seem like overkill for individual users. (Again, though, many people find Word’s “Track Changes” feature indispensable once they begin using it.) But version control systems can be used quite straightforwardly in a basic fashion, and they can often be easily integrated with your text editor, or used via a friendlier application interface that keeps you away from the command line. The core idea is shown in Figure 2.1. You keep your work in a repository. This can be kept locally, or on a remote server. As you work, you periodically stage your changes and then commit them to the repository, along with a little note about what you did. Repositories can be copied, cloned, merged, and contributed to by you or other people.
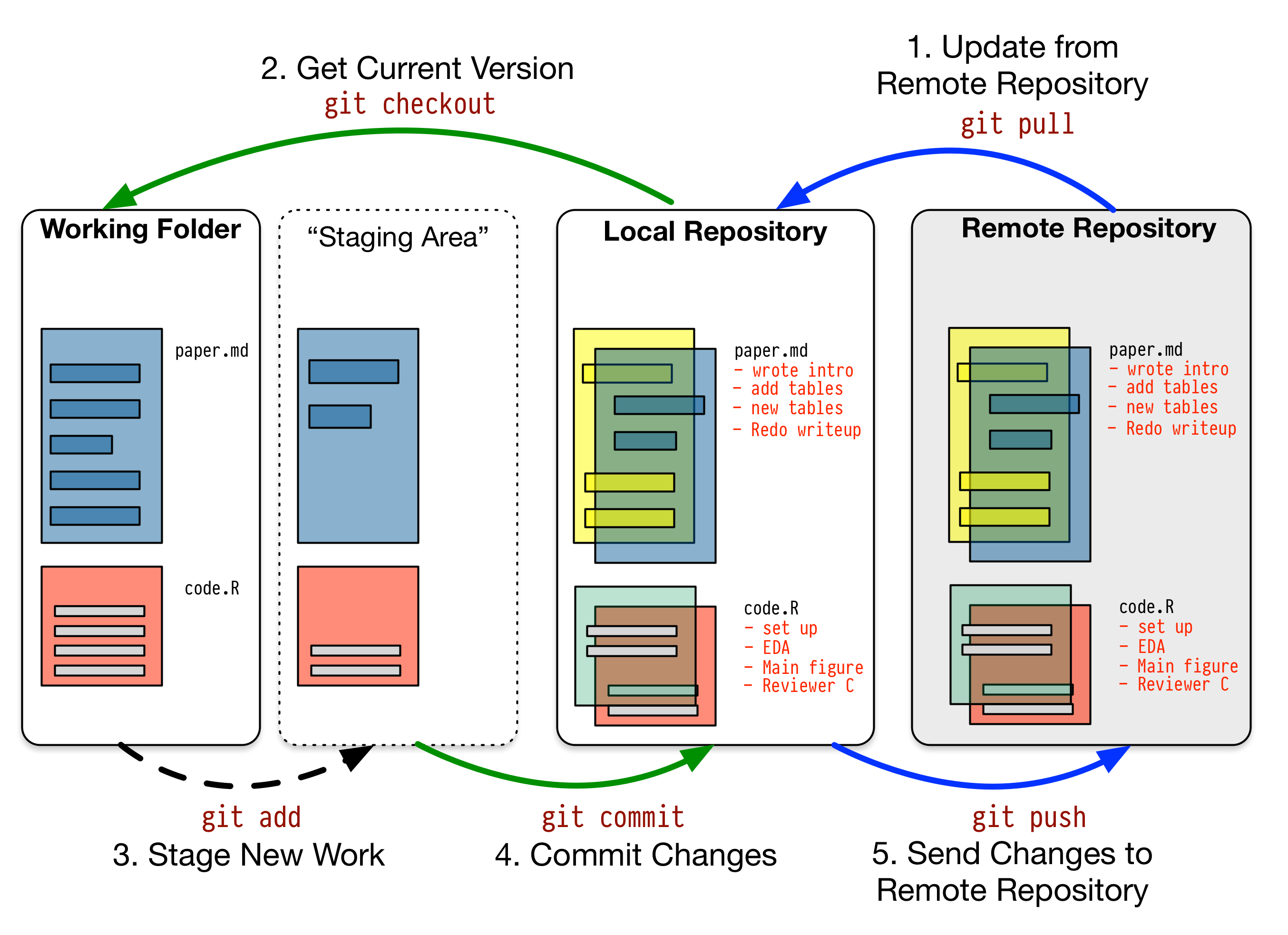
Figure 2.1: A schematic git workflow.
Figure 2.1 describes a schematic git workflow. You get the most recent version of your project from a remote repository (such as GitHub), and then “check-out” the project to work on, writing your code or text. You work on your files as usual in a folder on your computer. But it is the repository that is “real” as far as the project is concerned. Once you are happy with the changes you have made to your documents you stage these changes. Behind the scenes, this means the changes are added to an index that Git uses to keep track of things. But these changes are not yet permanently recorded. To make them permanent, you commit the changes to the repository, along with a note about what you did. You now have a firm record of your actions. You then “push” the changes up to the remote repository, which in effect also functions as a backup of your work. Over time, the repository comes to contain a complete record of the project, any step of which can be revisited as needed. In the simplest case there is no remote repository, only a local one you check out and commit changes to. You can do all this from the command line, or use one of several front-end applications designed to help you manage things.
Revision control has significant benefits. A tool like Git combines the virtues of “track changes” with those of backups. Every repository is a complete, self-contained, cryptographically signed copy of the project, with a log of every recorded step in its development by all of its participants. It puts you in the habit of committing changes to a file or project piecemeal as you work on it, and (briefly) documenting those changes as you go. It allows you to easily test out alternative lines of development or thinking by creating “branches” of a project. It allows collaborators to work on a project at the same time without sending endless versions of the “master” copy back and forth via email. And it provides powerful tools that allow you to automatically merge or (when necessary) manually compare changes that you or others have made. Perhaps most importantly, it lets you revisit any stage of a project’s development at will and reconstruct what it was you were doing. This can be useful whether you are writing code for a quantitative analysis, managing field notes, or writing a paper. While you will probably not need to control everything in this way, I strongly suggest you consider managing at least the core set of text files that make up your project (e.g., the code that does the analysis and generates your tables and figures; the dataset itself; your notes and working papers, the chapters of your dissertation, etc). As time goes by you will generate an extensive, annotated record of your actions that is also a backup of your project at every stage of its development. Services such as GitHub allow you to store public or (for a fee) private project repositories and so can be a way to back up work offsite as well as a platform for collaboration and documentation of your work.
After you download and install Git—e.g., by installing Apple’s developer tools—the easiest way to get up and running with it is to create a GitHub account and then configure git and GitHub. While git is free software; GitHub is a commercial service with a free tier.
Why should you bother to do any of this? Because the main person you are doing it for is you. Papers take a long time to write. When you inevitably return to your table or figure or quotation nine months down the line, your future self will have been saved hours spent wondering what it was you thought you were doing and where you got it from.
2.3 Back Up Your Work
Regardless of whether you choose to use a formal revision control system, you should nevertheless have some kind of systematic method for keeping track of versions of your files. Version-controlled projects are backed-up to some degree if you keep your repository somewhere other than your work computer. But this is not nearly enough. Apple’s Time Machine software, for example, backs up and versions your files on your disk, or to a local hard drive, allowing you to step back to particular instances of the file you want. This still isn’t enough, though. You need regular, redundant, automatic, off-site backups of your work. Because you are lazy and prone to magical thinking, you will not do this responsibly by yourself. This is why the most useful backup systems are the ones that require a minimum amount of work to set up and, once organized, back up everything automatically without you having to remember to do anything. This means paying for a secure, offsite backup service like Crashplan, or Backblaze. Offsite backup means that in the event (unlikely, but not unheard of) that your computer and your local backups are stolen or destroyed, you will still have copies of your files. I know of someone whose office building was hit by a tornado. She returned to find her files and computer sitting in a foot of water. You never know. Less dramatically, but no less catastrophic from the point of view of one’s work, I know people who have lost months or even years of work as a result of dropping a laptop, or having it stolen, or simply having their computer (or “backup drive”) fail for no apparent reason. Like seat belts, you don’t need backups until you really, really need them. As Jamie Zawinski has remarked, when it comes to losing your data “The universe tends toward maximum irony. Don’t push it.”